
RMDB系统文档
rmdb.cpp
rmdb.cpp定义了服务端的流程,除了端口连接的部分,每一个连接都会打开一个循环,循环每次接收客户端的一条输入语句,判断特殊语句之后,将视为sql文件,经过parse、analyze、plan、execute四个阶段进行执行。
同时rmdb.cpp为每一条语句生成一个上下文,并按照是否为单挑语句设置事务。
由于客户端可以视作简单的字符串发送接收器,因此全部的事务由rmdb.cpp负责执行,模块的导入都在rmdb.cpp中完成。
系统定义
前端
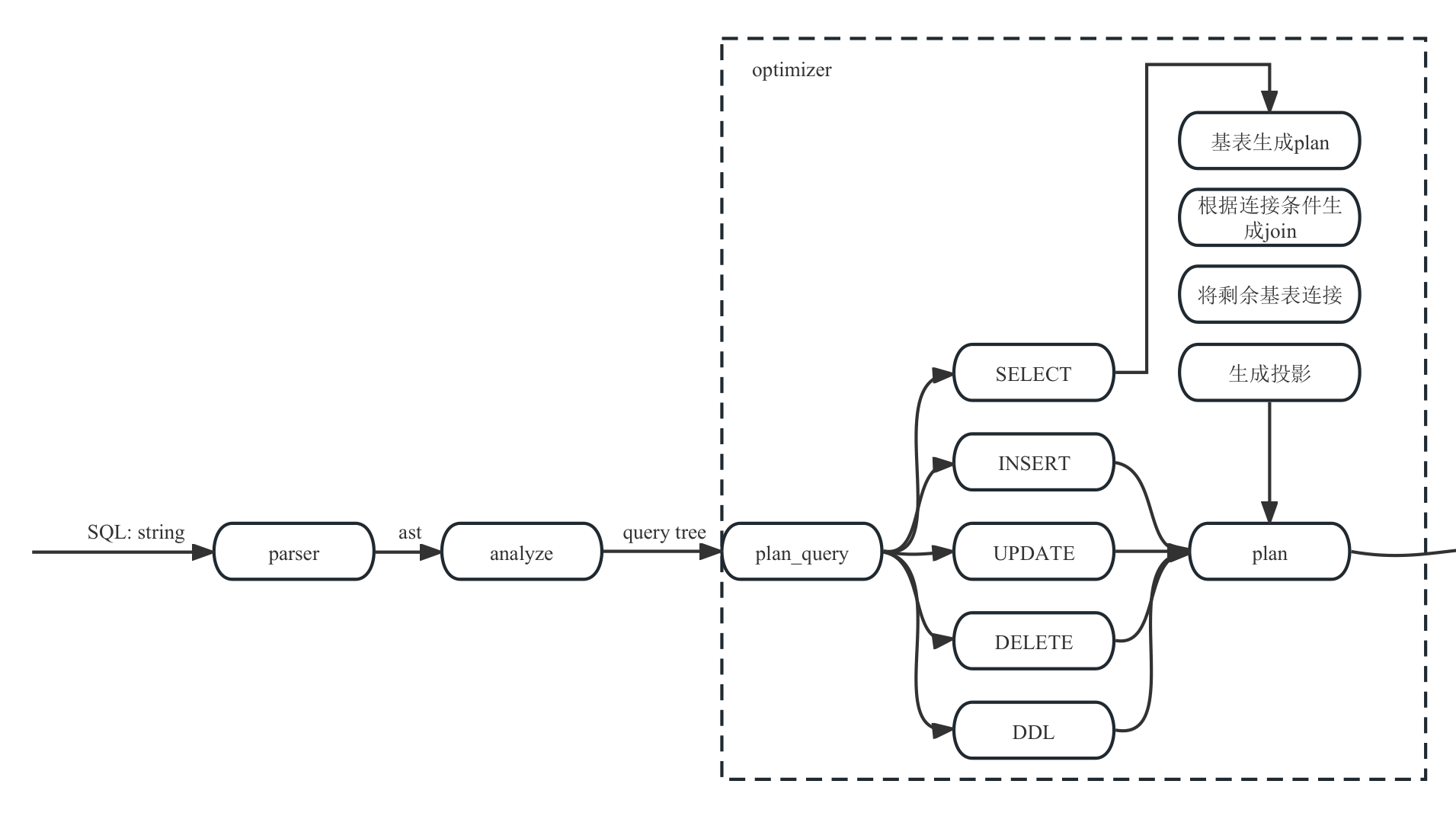
RMDB系统的前端负责接收SQL语句,生成对应的Plan对象,并将这些对象传递给后端进行实际的执行。
Parser
Parser负责将SQL语句转化为抽象语法树,类似于语义分析。使用Flex和Bison插件来完成从字符串到抽象语法树的转化,并得到一个根节点。Flex和Bison通过全局的变量来传递:
std::shared_ptr<TreeNode> ast::parse_tree;
因此需要上锁,调用的情境如下:
bool finish_analyze = false;
pthread_mutex_lock(buffer_mutex);
YY_BUFFER_STATE buf = yy_scan_string(data_recv);
if (yyparse() == 0)
{
if (ast::parse_tree != nullptr)
{
try
{
std::shared_ptr<Query> query = analyze->do_analyze(ast::parse_tree);
yy_delete_buffer(buf);
finish_analyze = true;
pthread_mutex_unlock(buffer_mutex);
}
}
}
if (finish_analyze == false)
{
yy_delete_buffer(buf);
pthread_mutex_unlock(buffer_mutex);
}
Flex插件对应src/parser/lex.l文件,里面定义了关键字匹配规则,决定了一条语句将会被提取出怎么样的语素(Token)。
Bison插件对应src/parser/yacc.y文件,里面定义了语法规则,决定了语素以什么样的顺序组织是合法的以及如何将一个语素序列转化为一个抽象语法树。
ast::TreeNode
ast::TreeNode是语法树的抽象节点,任何节点继承于此。节点的类型本身就是一种信息,同时节点的字段提供了节点的详细信息。
节点的定义通过SemValue这个结构体与Bison插件进行映射,成员的名称作为Bison插件中的类型指代,而成员的类型是Bison的语法对象最终构建的类型(如在Bison中,sv_int代表着int节点),每一条语法规则都有自己的类型。
struct SemValue
{
int sv_int;
float sv_float;
std::string sv_str;
bool sv_bool;
std::vector<std::string> sv_strs;
std::shared_ptr<TreeNode> sv_node;
SvCompOp sv_comp_op;
std::shared_ptr<Value> sv_val;
std::vector<std::shared_ptr<Value>> sv_vals;
std::shared_ptr<Col> sv_col;
std::vector<std::shared_ptr<Col>> sv_cols;
};
#define YYSTYPE ast::SemValue
Query & Plan
Query和Plan是从解析的语法树到实际执行的Executor之间的中间产物,负责提取SQL语句的实际功能并按需分组。
Query
Query是对SQL语法树的统一的表示,通过Analyze对象生成,接口是:
std::shared_ptr<Query> Analyze::do_analyze(std::shared_ptr<ast::TreeNode> root);
Query对象包含了根节点本身,这些根节点用于在创建Plan的时候提供语句类型以作出区别。
Analyze
Analyze主要用于分析DML和Load语句,检验SQL语句中的语义错误,比如不存在的列,二义性的列,并从Ast语法树的结构中提取出统一的,易于利用的信息。对于其它语句,Analyze则什么也不做,直接传递Ast语法树到Plan生成部分。
Plan
Plan及其继承类是对Query进行进一步优化得到的结果,且不再包含Ast节点和Query对象引用,在数据存储上尽量减少了冗余。从结构上看,它和最终生成的Executor十分类似,可以视作是各种Excutor生成的初始化条件对象。
Plan生成的接口如下,其中DML语句的详细生成由Planner对象进行。
std::shared_ptr<Plan> Optimizer::plan_query(std::shared_ptr<Query> query)
std::shared_ptr<Plan> Planner::do_planner(std::shared_ptr<Query> query);
Planner
Planner负责DML描述语句执行的层级结构,特别是对于复杂的Select语句,Planner需要进行语义上的优化来减少Select中间体的大小,元组数目来提高效率。
在Task5中实现的规则有:
- 选择下移:对于单个表的Scan方案,将等号右边为数值,左边为该表属性的条件下放到ScanPlan中,以减少中间体数目。
- 投影下移:对于单个表的Scan方案,预先进行一次投影的封装,保留最后选择的属性、用于条件判断和分组的属性,其余属性全部去除,以减少S中间体大小。
- 连接排序:对于表之间的Join方案,首先通过RmFileHandle来依次读取表中元组数并排序,按照从小到大的顺序决定连接的顺序,以减少中间体数目,并尽可能的下移连接条件。
在决赛中添加的规则有:
- 条件替换:如果出现表之间的属性相等条件(A.B = C.D)和其中一个属性的等值条件(C.D = X),可以去掉等值条件将属性相等条件通过代入法替换成一个等值条件(A.B = X),从而使本来无法通过索引扫描的表变为索引扫描。
后端
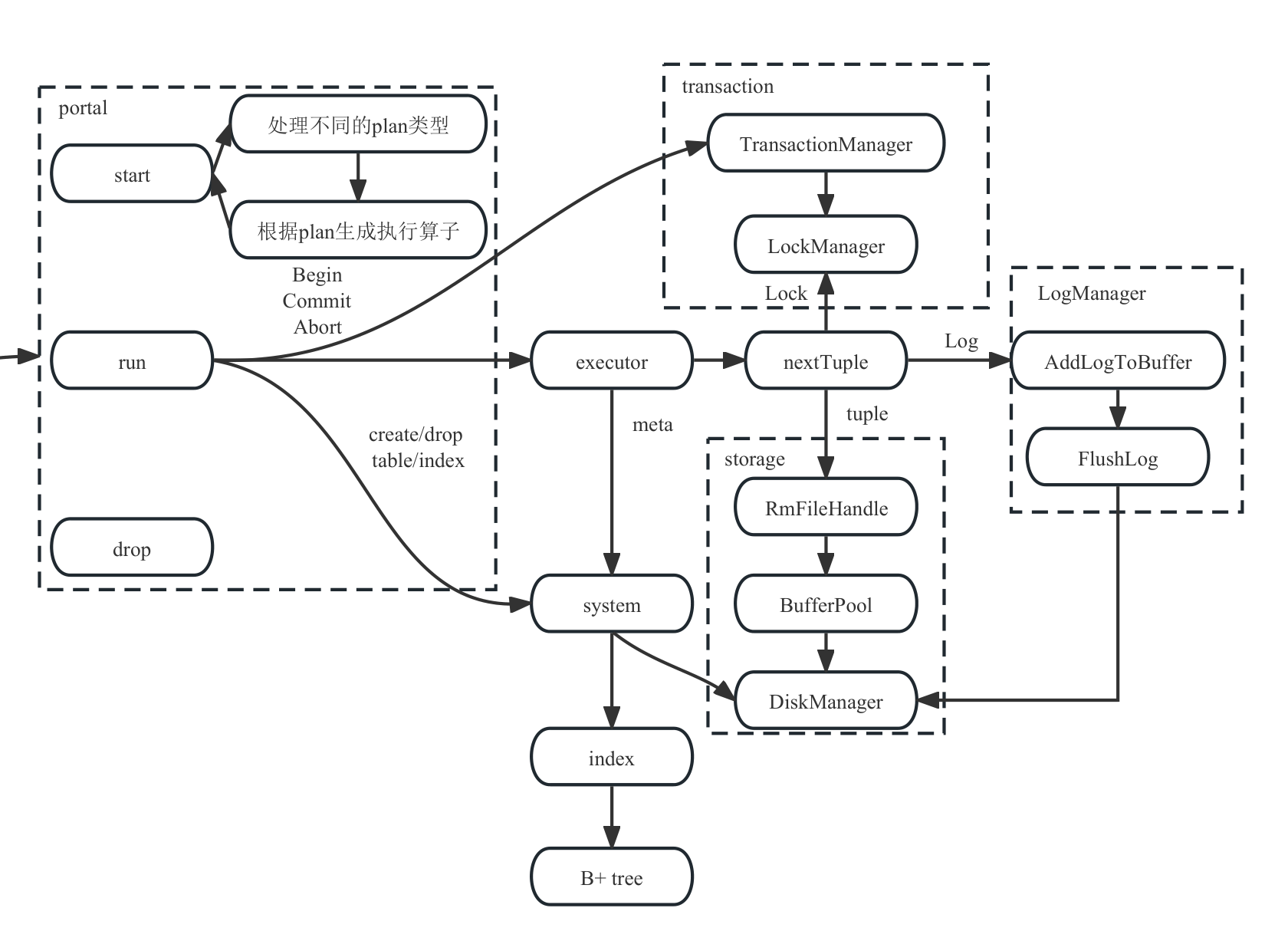
RMDB系统的后端负责实际执行语句,并写入执行结果以供client_handler反送回客户端。
Portal
Portal是接收Plan构建Executor并实际执行语句的中间体,是连接抽象层和实现层之间的桥梁。Portal的接口是:
std::shared_ptr<PortalStmt> start(std::shared_ptr<Plan> plan, Context *context, TransactionManager *txn_manager);
void run(std::shared_ptr<PortalStmt> portal, QlManager *ql, txn_id_t *txn_id, Context *context);
start用于生成根据Plan生成PortalStmt,对于DML语句来说还伴随着Executor的生成。而run函数则执行PortalStmt,根据种类来决定使用哪一个执行模块。大致分为DML、DDL、事务,分别对应ExecutionManager,SmManager,TransactionManager。
对于DML语句,首先判断语句种类,根据不同的语句构建不同的Executor:
- Insert语句:直接构建InsertExecutor。
- Delete/Update语句:根据条件和表名构建SeqScanExecutor/IndexScanExecutor,执行一轮之后按照获取的Rid集合构建DeleteExecutor/UpdateExecutor。
- Select语句:照着Plan的结构翻译即可,Select用上的每一种Plan都能找到对应Executor。
对于DDL语句,直接调用SmManager对应的创建/删除/查询函数即可。
对于事务语句,直接调用TransactionManager的abort,commit函数即可。
SmManager
SmManager是RMDB系统的底层管理器,任何底层操作都要通过SmManger为中介来执行,而任何组件之间的调用都需要SmManager提供指针,任何和表/索引元数据的获取都需要SmManager提供,因此SmManager可以说是数据库的中枢控制器。
SmManager包含了BufferPoolManager、DiskManager、IndexManager和RmManager。后二者用于对索引和表进行实际的文件操作,而数据库级别的操作由SmManager内部调用命令行语句完成。
Storage
存储模块主要负责将提供程序运作时的页,并将程序的修改同步到硬盘以持久化。其他模块在运作的时候,是不需要关注存储实现的细节,只需要提出获取页、开闭文件、创建文件的要求,由存储模块实际执行。
Page
Page(页)是磁盘文件最基本的存储单位,表和索引文件都以Page的形式存储并以页的形式进行访问。页本身的序号具有意义,因此无论页处于何处,以何种形式处理,都可以通过唯一的编号PageId来定位。
PageId指出了是哪一个表(索引)的哪一个Page,可以通过计算式 PAGE_SIZE * PageId.pageno 来方便的定位Page的起点。Page本身不解释其中的内容的含义,只有通过FileHandle进行封装才能执行有意义的页操作。
DiskManager
DiskManager负责开闭文件以及以Page为单位进行读写,使用的是C底层文件流实现以及对系统终端的调用。
DiskManager的操作是最基本的操作,任何文件相关操作都需要通过调用BufferPoolManager来具体的实现。
只有绕开BufferPoolManager直接调用disk_manager的情况下不用考虑pin和unpin的问题。
BufferPoolManager
缓冲池是负责向上层提供具体页并接收指令写回具体页的模块,是对内存中Page进行管理的对象。
缓冲池可以进行固定页和解绑页,被固定的页不会被纳入替换的列表中。而未被固定的页可以被访问,但是当需要读取新页而缓冲池已满的时候,通过LRU的算法从未被固定的页中选取一份替换,若为脏页则先写回硬盘,而对页的读写操作实际还是由DiskManager执行。
缓冲池中pin和unpin就像new和delete一样,需要配对。如果缓冲池中所有页面被固定而此时又有对缓冲池中没有的页进行请求,那么这个请求失败,事务回滚。因此,一旦不需要页的内容,就要及时unpin,减少pin_count。new_page和fetch_page两个函数会增加pin_count,只有也只应该有FileHandle调用了这些方法。
Page* BufferPoolManager::fetch_page(PageId page_id);
Page* BufferPoolManager::new_page(PageId* page_id);
Pin和Unpin应该由FileHandle成对地封装在接口中以保证没有页泄漏,尽管目前在planner和scan文件中PageHandle被作为返回值供调用者使用,更合理的做法是提供外部接口直接满足其他对象的需求,而不是返回一个PageHandle将Unpin的职责转移给调用方。
RmManager
RmManager是对表文件进行统一管理的对象,负责表文件的创建、销毁、打开和关闭。打开的过程获得一个RmFileHandle,其中包含了RmFileHeader。除了在planner中为了根据元组数量优化连接顺序调用了RmManager的函数,其他时候都是由SmManager对其进行封装并调用,这一点应该上升到强制通过SmManager调用。
RmFileHandle
文件句柄是对于一个已经打开的文件,能够对其进行读写的中间对象,分为索引句柄和表句柄,RmFileHandle是表句柄。RmFileHandle包含RmFileHeader,其中包含了表的元数据,这些是不可修改的,且存放在表文件的0号页。
RmFileHandle支持按Rid进行操作如update_record,delete_record,也可以通过页号获取页句柄RmPageHandle。RmPageHandle是对表中的具体页进行管理的对象,通过调用BufferPoolManager接口获取Page并封装。
RmPageHandle
RmPageHandle包含了页的信息以及原始数据,基本上只在遍历的时候用上,使用其中的slot来遍历页并获取下一张页的信息。一般用于遍历或者计算元组数量使用,如果要修改某个页的内容,请通过RmFileHandle提供的接口来进行。
每一个RmPage分为三个部分RmPageHeader、Slot、Data,分别保存了页的元数据,槽位bitmap,元组数据。
RmRecord
RmRecord是元组在内存中的存在形式,元组本身只有data这一部分,也就是纯粹存储信息的一段紧密01数据,而通过赋予size,allocated信息使得其能够被赋予使用意义并有效管理。但修改一个从RmFileHandle得来的RmRecord对象或者其指针引用并不会将改变写到内存中,因为RmRecord的几乎所有构造方式都是复制数据。
RmScan
RmScan是实际对记录进行扫描的对象,每次获得一个Rid的时候,都会先检查其版本记录,根据最新可见版本是否存在,是否删除决定元组是否可见。
在判断可见性的过程中如果要回溯的话会首先访问一次版本记录,于是将此次记录先缓存,以免在Next()函数调用时再进行一次回溯。同时改进原本的std::vector
IxManager
IxManager和RmManager类似,是对索引文件进行底层管理的对象,相比而言增加了一些判断函数用于实际执行中选择索引。
IxFileHandle
IxFileHandle是对于索引文件而言的,支持通过key的方式查询唯一性和调整索引结构。IxFileHandle包含IxFileHeader,其中包含了索引的元数据,这些是不可修改的,且存放在索引文件的0号页。每一个节点存放了若干个键,在叶节点中存放着对应的元组Rid,也是索引实际存放的内容,即按照key的顺序在B+中按树叶节点遍历的位置存放元组的唯一标识。
除了fetch_node之外的所有未被外部调用的接口都满足Pin和Unpin成对,在别的分支有过修改,将唯一在IxScan中的调用搬到IxFileHandle内部实现,最终满足外部接口不返回IxNodeHandle,缓冲池不泄露。
IxNodeHandle
IxNodeHandle实际上和RmPageHandle一样,包含了页的信息以及原始数据,但是由于索引文件中每一个页都是一个B+树节点,因此得名NodeHandle。IxNodeHandle支持查询和插入删除等功能,修改力度较小。
IxNodeHandle一样拥有自己的三部分数据:IxPageHeader、keys、rids,分别保存了页的元数据,键,元组的Rid值。
IxScan
IxScan继承自RmScan,IxScan不同的作用就是按照给定的Iid开始和终点遍历叶节点,从而缩小Rid的范围。也就是说,RmScan每次Rid自增的设定由IxScan升级为在索引中查找下一个符合某些条件的Rid,而根据Rid获取元组的功能依旧没有改变,所以可以复用部分代码。
Executor
LoadData
LoadData执行器采用快速读取的方式从csv文件中逐行转化为RmRecord。首先会在主线程中按行读取string并放到一个集合中,每当这个集合内容达到上限时,就分配一个任务,并向RmFileHandle预分配一个界面。读取完所有的行后,会通过多线程来领取并完成给定的任务,实际是将string处理并插入到对应任务的预分配页面中。
在插入到表文件之后,需要收集每一个索引的每一个键值对,这通过获取RmFileManager的所有Page进行,然后进行排序,调用索引的bulk_load来一个一个索引的加载。使用bulk_load的时候,会先建立素有叶子节点层,然后递归的向上建立节点。
FastCount
FastCount执行器直接从对应表中的文件头中读取一个记录元组数量的变量,然后构建一个RmRecord返回,而在插入和删除的时候负责维护这个值。
Sort
Sort执行器先遍历一轮子Executor获取所有元组,然后进行一次Sort,最后一个一个按顺序返回即可。
Aggregation
Aggreation执行器在beginTuple中先遍历一轮子Executor获取所有元组,然后按照分组的字段进行分类,最后依次输出。
Projection
Projection执行器直接对于子Executor得到的RmRecord进行部分复制,从而做到减小元组大小,筛选出目标属性。
Insert
Insert执行器先根据传入的变量构建一个Rmrecord,然后直接调用RmFileHandle执行插入,并且当场插入索引。
SeqScan
SeqScan执行器构建了一个RmScan对象,通过其next、end、Next接口来分别步进、判断结束和获取RmRecord,对于获取到的RmRecrod,执行器需要判断其是否符合筛选条件,如果需要上锁,会在扫描到一条符合的元组的时候就对其上锁,考虑到可能要排队,排队的过程中肯定有别的事务修改了元组,因此获取锁之后还需要进行再验证,即再次判断元组是否符合条件。只有在SeqScan是用于收集Update和Delete的Rid时才会设置上锁选项。
在实际的Tpcc测试中,由于针对语句进行了优化,SeqScan并没有实际被用上。
IndexScan
IndexScan执行器构建了一个IxScan对象,同样通过其进行实际的探查、获取。在构建之前,需要根据使用的索引和条件来生成key的范围,通过两次查询获取起点和终点的Iid并传递给IxScan。其余的过程和SeqScan类似。
在提交分支之外有一处优化,如果按照索引的属性顺序排列有连续的等值条件或者不等值条件(不等值条件一定是连续的最后一个),那么得到的元组一定满足这些条件,那么不需要再次验证,可以从待验证的条件中删去。
NestedLoopJoin
NestedLoopJoin执行器先遍历一边右孩子,找到满足连接条件的元组拼接并返回,再让左孩子步进,直到左孩子结束。
Limit
Limit执行器通过简单的计数,在遍历完子查询的输出或者达到限制后宣告end来进行数量限制。
Delete
Delete执行器在获取到Rid集合之后,直接构建一个带删除标记的TupleHeader写回对应的Rid元组位置,不当场删除索引。
Update
Update执行器在获取到Rid集合之后,直接构建一个完整RmRecord写回到对应的Rid位置,非事务模式下不涉及索引。
Transaction
时间戳
全局时间戳是一个每次被访问就会+1的变量,在开启一个事务时以及结束一个事务时都会访问全局时间戳,这样可以保证时间轴的运转是一直向前的,不存在时间戳相同引起的复杂判断。同时TransactionManager有两个map:
std::unordered_map<timestamp_t, txn_id_t> TransactionManager::commit_map;
std::unordered_map<txn_id_t, timestamp_t> TransactionManager::commit_time;
这两个map用于通过相互转换结束时间戳和获取事务ID,结合函数CheckIfCommitted来判断事务的性质。
持久化UndoLog
每个事务的UndoLog存储的是这个事务修改的元组本来的样貌和时间,当事务完成之后,Transaction对象不再存在,但是UndoLog仍然需要被保存,以供版本链的回溯。利用map:
std::unordered_map<txn_id_t, std::vector<UndoLog>> TransactionManager::txn_undos;
可以从内存中读取过去的UndoLog。UndoLog的保存规则是,谁覆盖谁保留原版本。
从内存卸除过时事务
反向map和UndoLog不能无限的存储,因为内存是有限制的。一个结束事务可以被卸除的充分条件是:
-
如果是提交的,在此事务提交之前开始的所有事务都已经结束。之后开启的任何事务访问到的版本一定不会早于此事务修改的,而UndoLog中的版本是更早的版本,故可以删除。所以需要维护一个当前最早开始的事务ID,由于事务开始时间和事务ID大小性一致,在每次提交的时候删除掉当前最早ID之前的所有事务记录。
-
如果是中止的,这个事务的所有UndoLog被恢复,所以不存在影响。
在此维护一个est变量表示最早开始的活跃事务,任何事务未结束的事务的元组ts都大于等于est对应事务的start_ts。在此之前提交的事务的提交信息也可以卸除了。
判断一个时间戳对应的事务是否提交的判据变为了:commit_map中存在时间戳或者时间戳小于est的start_ts。
MVCC&Lock
TupleHeader
TupleHeader是附加在每一个元组属性上的字段,
无锁读
MVCC的精髓就是无锁读,在快照隔离的情况下,只需要验证时间戳就可以获取可见性。
有锁写
按照冲突直接abort的要求,如果一个事务先修改了元组T1,而另一个后来的事务也向修改T1,那么会直接abort并会一直发生直到第一个事务结束。也就是说,只有这个事务在第一个事务结束后再开始才能不abort地修改。
上述存在的问题是:
- 重做浪费了很多资源,可能出现了资源抢占的现象
- 难以把握重做的频率,导致第一个事务结束和第二个事务不冲突的那一次的开始时间之间有间隙
所以考虑加锁,当后来的事务试图修改同一个元组时,需要等待已有的锁释放,之后再次检验加锁的元组是否满足需求,若不满足,则取消更改此元组即可。这里的效果是等效的。